Dit Labbook behoort bij het project [Zoeken, Sturen en Bewegen]
0435899 nout Niels Out 0440949 acranenb Andreas van Cranenburgh
Ons project gaat over [Sudoku]. We zullen deze puzzel algoritmisch proberen op te lossen. Als dit lukt, willen we het uitbreiden met vergelijkingen tussen verschillende puzzels.
Een puzzel bevat een aantal gegeven waarden, het doel is dan om de rest in te vullen. Doorgaans zijn de gegeven waarden zo gekozen dat er maar een oplossing is voor een puzzel.
Sudoku is in Nederland bekend geworden doordat deze puzzels dagelijks in de Sp!ts te vinden zijn.
Voorbeeld:

We gaan een programma schrijven om Sudoku puzzels op te lossen. Dit doen we in C en Prolog. Hierna vergelijken we de twee programma's op bijvoorbeeld snelheid en leesbaarheid.
We gaan uit van de brute force methode, domweg alle mogelijke waarden invullen. Met alle mogelijke waarden wordt bedoeld waarden die nog niet eerder in dezelfde regel, kolom of regio zijn gebruikt.
We verwachten dat C sneller zal zijn dan onze Prolog versie, omdat Prolog langzaam is.
Hierna gaan we een puzzel die relatief lang duurt om op te lossen, simpeler maken door meer/minder vakjes open te laten in het begin. We verwachten dat een versie met minder vakjes open sneller op te lossen is. Bovendien vermoeden we dat als we meer vakjes openlaten, dat er ook meerdere mogelijke oplossingen zijn.
o C: https://unstable.nl/andreas/c/sudoku.c gebruik: ./sudoku <file.txt o SWI-Prolog: http://student.science.uva.nl/~nout/sud.pl gebruik: start('file.txt'). o GNU prolog versie: https://unstable.nl/andreas/prolog/sud.pl [binary] gebruik: ./sud file.txt
o Prolog code met constraints (niet door ons gemaakt, vergelijkingsmateriaal: https://unstable.nl/andreas/prolog/sudoku.notours.pl
Begonnen met opzet van het C programma. Bestandsformaat voor puzzels bedacht: negen karakters per regel, negen regels. Lege vakjes zijn spaties of nullen. Voor prolog wordt hetzelfde formaat gebruikt, zodat dezelfde puzzles makkelijk te vergelijken zijn met beide talen.
Het programma lost puzzels op met maximaal 41 ontbrekende waarden. Bij meer ontbrekende waarden geeft het programma het om onduidelijke redenen op.
Het C programma verder bewerkt. Na een paar kleine verandering lost het programma alle sudoku's op. Wel is het algoritme nog zeer inefficient, soms is de maximale recursie wel 70.000. Desalniettemin worden alle puzzels in minder dan een seconde opgelost!
Prolog code kan simpele sudoku's oplossen, moeilijkere duren erg lang (te lang).
Prolog code kan meeste sudoku's snel oplossen, sommige duren echter nog vrij lang.
Samen naar robotvoetbal-wedstrijd gekeken ter ontspanning.
Een idee om nu uit te voeren is een groostchalige meting. We nemen een collectie van Sudoku puzzels met oplopend aantal ontbrekende vakjes. Dan kijken we hoe snel de programma's deze puzzels kunnen oplossen. Om de meetresultaten betekenis te geven moet elke puzzel bijv. 100 keer worden opgelost, anders zijn de resultaten niet significant. De resultaten zetten we dan uit in een grafiek.
Command line opties toegevoegd aan het C programma:
o -g genereer een puzzel. o -s x geef oplossing nummer x. o -n x los puzzel x maal op.
Prolog code aangepast om ook met GNU prolog te werken. De reden hiervoor is dat GNU prolog programma's kan compileren naar native executables. Hierdoor zal de vergelijking met C veel eerlijker worden.
's Avonds VIA-BBQ met waarschijnlijk veel bier.
Gisteravond was erg gezellig, maar we zijn wel net als voorgaande dagen voor 11 uur al weer aan het werk op de universiteit. Het blijkt dat de gecompileerde versie van het Prolog programma inderdaad veel sneller werkt. We hebben op internet ook een erg snelle prolog code gevonden die met constraints werkt, waarmee we ook gaan vergelijken.
De puzzelgenerator van de C code kan nu een opgegeven aantal waarden wegstrepen, zodat de moeilijkheidsgraad is te bepalen. Met het volgende commando hebben we nu 40 puzzels gemaakt om de meting mee te gaan doen:
COUNTER=50; until [ $COUNTER -lt 10 ]; do; ./sudoku -g $COUNTER >puzzle$COUNTER.txt; let COUNTER-=1; done
Het resultaat is een 40-tal bestanden, puzzle50.txt tot en met puzzel10.txt, met allemaal verschillende puzzels in oplopende moeilijkheidsgraad.
Na metingen bekeken te hebben, vallen wat dingen op, zie discussie hierover.
2:13 --> We hadden dus de user time ipv de total moeten gebruiken om te checken welke sneller is, maar we hadden ook naar bed moeten gaan.
Dit doen we nu dus ook, welterusten!
We gebruik van de volgende software voor ons project:
- Linux
- GNU C compiler
- GNU Prolog
- SWI prolog
- Kwrite to edit the code :P
Apparatuur die we gebruikt hebben:
- Personal Computer van Dell, zoals aanwezig op universiteit
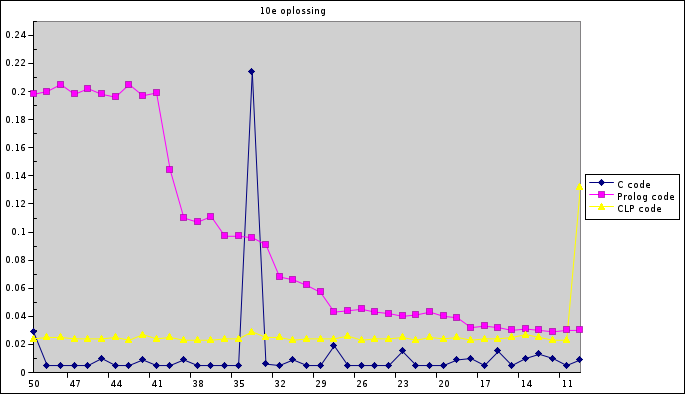
Opvragen van de eerste 10 oplossingen:
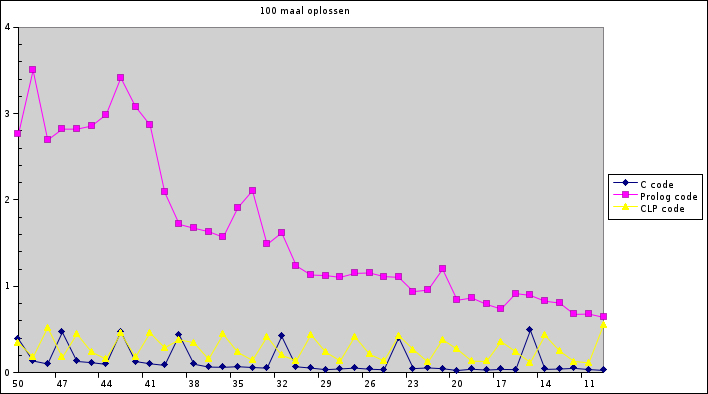
100 maal oplossen:
Er zijn wat meetwaarden die duidelijk niet kloppen in de grafieken. Onder andere de hoge piek bij 34 is vreemd. We vermoeden dat dit komt door onze manier van de tijd meten, we hebben niet veel tijd hierin gestoken om te kijken of dit wel altijd klopt. Volgens de meting 2% cpu 0.214 total die bij 34 hoort, was de cpu voor slechts 2% in gebruik, gedurende 0.214 seconde, wij gingen er echter vanuit dat deze 0.214 het aantal seconden was dat de cpu geheel gebruikt werd.
Onze verwachting dat C sneller is dan Prolog lijkt te kloppen. Wel zit de Constraints versie van prolog er zeer dichtbij. Het is goed mogelijk dat het verschil in tijden tussen deze twee komt door de tijd die het inlezen van de files inneemt. Bij de 100 maal oplossen vertonen zowel de C versie als de constrains Prolog code kleine piekjes, die redelijk regelmatig lijken, dit komt misschien ook wel door de manier van meten. Onze eigen prolog code is duidelijk langzamer, alhoewel we er al veel aan geoptimaliseerd hebben.
Het klopt bovendien dat een puzzel met weinig open vakjes sneller is op te lossen, wat echter alleen bij onze prolog versie te zien is. Bij de C en de andere prolog code gaat er waarschijnlijk te veel tijd verloren met bijzaken als de puzzel inlezen.